|
孙显斌
中国科学院自然科学史研究所研究员
古籍数据库的应用,主要有两个方面:分别是学术研究和文化普及。就目录古籍数据库而言,目前主要还是学术方面的应用。既然如此,我们就要回顾古典目录学的“初心”是什么,也就是它如何支撑学术研究。搞清楚这些,就给我们建设古籍目录数据库提出了基本任务。如果我们用数字人文的方法,连传统目录学能够支撑的学术研究都做不到的话,那显然是不能让人满意的。
古典目录学的理论和实践,余嘉锡《目录学发微》给出了较完整的概括。首先,我们现在提到的书目大多是指多书目录,但实际上目录有两个含义。第一个含义是一本书的目录,也就是我们经常说的叙录,即单书目录。单书的叙录主要包括这个书的提要,再加上篇目。这里的篇目特别重要,一共有多少篇,每篇的标题是什么。第二个含义是多书目录,多书目录包含多条书目,它一般包括每本书的题名和作者,有的书也没作者,但至少要有书的题名。早期的多书目录,刘向《别录》、郑默《魏中经簿》和荀勖《晋中经新簿》就应该都包括每本书的篇目,但是后来的叙录就只有提要没有篇目了。我为什么强调篇目呢,应该说这是刘向、刘歆父子为我们建立的一个很好的传统。每本书的叙录带上篇目,如果这本书亡佚了,我们还可以通过篇目了解更多这本书的内容,包括书的结构,帮助做辑佚工作。为什么后来的叙录不再包括篇目了呢?可能是因为著录书籍的数量迅速增长,叙录里如果包括篇目,那么一部多书目录的篇幅就太大了。
接下来的问题是,在多书目录中众多条目如何排列——主要依靠分类和类内排序。多书目录都要有分类,如果没有分类,这个目录就很怪,就从头抄到尾,这种只能算是一种记账式的簿录,在中国古代这种情况很少见。有了分类,就会有小序,介绍每个部类的学术源流和内涵。中国的传统目录一直不是仅作为记账簿录而存在,而是从源头就与学术史密不可分,也就是章学诚所谓的“辨章学术,考镜源流”。与学术史紧密相关,这是中国传统目录学的核心特点之一。我们讨论古籍分类的流变比较多,因为它与学术史密切相关。但是分类的依据是什么?台湾学者周彦文指出古籍分类的维度有两个,分别是内容和体裁。大多数情况下古籍是按照内容分类的,但是集部基本上是按照体裁分类的,楚辞、总集、别集、词曲类等,其他比如史部的纪事本末类、子部的类书类等也是按照体裁分类的。类之间以及类内的书目顺序,一般是按照时间、空间和逻辑的顺序排列。以上即是古典目录学的理论,我们运用数字人文的方法解读古籍目录数据,就要从这些维度进行考察和分析。
至于古典目录学的实践,首先是查找一类之书。假如我是研究音乐的,宋代以前音乐的书有哪些?我们查《新唐书·艺文志》经部乐类就有61种,这里面包括亡佚的,即曾经存在的书。《新唐书·艺文志》属于品种目录,此外还有版本目录,在版本目录中可以查找一种书的各个版本;导读类的书目,比如《书目答问》;提要类书目,比如《四库总目提要》;我们可以通过阅读一类书的目录和提要了解相关的学术概况和发展史。其次是查找一书的著录,即同一部书在不同目录中的著录。也举一个音乐类古籍的例子,如智匠的《古今乐录》。它在《隋书·经籍志》《旧唐书·经籍志》《新唐书·艺文志》《宋史·艺文志》中都有著录,在其后的目录中就不见著录了,只有《清史稿艺文志及补编》列举了此书的辑本,一般我们认为它应该亡佚于南宋。我们通过考察一书之著录,可以查找其提要,获取其篇卷分合情况,分析其所属类目的演变,有时还要辨析其亡佚时代。在“经籍指掌——中国历代典籍目录分析系统”中我们就可以实现这些功能,还可以跨目录综合检索,这样才能体现数字人文的先进性。
在弄清楚古典目录学的理论和实践之后,我们需要回顾一下古籍目录数据库建设的历程。在现代图书馆中,古籍最早的编目形式也是目录卡片,在编目电子化的大潮中,卡片变成MARC数据,古籍目录也跻身电子目录,可以与其他书一起联合检索。但是我们都知道MARC数据的格式是针对现代书籍设计的,不能完全适应中国传统线装古籍的著录。有一些项目不方便揭示,只好放在备注项里。专门为传统古籍作电子编目的方案于是应运而生,就我所知,最早的是北京大学图书馆古籍部建设的“秘籍琳琅”网站,后来扩充建设成“学苑汲古——高校古文献资源库”。它始建于21世纪初,时间非常早,目前有28所高校加入,是大家常用的一个古籍目录数据库。该数据库专门为古籍设计了一套著录规范,还提供了高级检索、浏览和索引功能,除可以按题名、责任者等索引查询以外,还可以按照版本类别、出版年代和出版地点进行浏览,也就是说系统必然对以上著录项进行了标准化。比“学苑汲古”稍晚,北京大学数据分析中心李铎团队,先是和国家图书馆合作开发“中国古籍善本书目线上查询系统”,其后双方又合作在2009年完成“中国历代典籍总目系统”,当时是想陆续建成一个历代典籍目录的系统,可惜只完成了第一期。该系统在市场上有售,不过购买的机构不多,很多人不知道或者没有用过。系统包括历代史志目录、《四库全书总目》《中国古籍善本书目》《丛书综录》等各种类型古籍目录二十七部,书目条目的数量超过二百万。系统提供浏览、检索和分析三大功能:按照标准分类、原目出处、成书时代、版本类型、版本时代进行浏览;检索条件包括书名、书目范围、分类、书目层级、版本类型、版本时代、责任信息、责任时间以及全文检索等,可以任意组合;还提供责任者相关性分析、成书年代分布统计分析、书目层次聚类分析等分析功能。为了实现这些功能,开发团队基于国际图联提出的“书目记录的功能需求”(FRBR:Functional Requirements of
Bibliographic Records)模型,将古籍分成品种、版本、印次和复本四个层次。还使用语义网知识库中的“本体”(Ontology)概念构建了中国古籍本体标准集,然后依此对古籍目录进行数据库化整理,并实现上述功能。在此之后,代表性的目录数据库有国家古籍保护中心的“全国古籍普查登记平台和发布平台”、上海图书馆的“中文古籍联合目录及循证平台”、中华书局古联公司的“中华古籍书目数据库”等。海外还有京都大学高田时雄先生主持开发的“日本所藏中文古籍数据库”,功能很简单,但是也是大家经常用到的。
最后,我们谈一下数字人文视野下古籍目录数据库的建设。图1是一个古籍数字化工作的示意图,从中可以看到古籍目录数据库的功能和地位。我们能够看到两个最基本的资源库即古籍目录库和古籍图像库,实际上古籍目录库更基本,因为它能够实现古籍图像资源的导航,这实际上也是目录最基本的功能,很可惜现在的目录库和图像库都没能链接起来。其实两者是不能分割的,古籍图像不仅要链接到书目上,还应该更进一步链接到书内的篇目上。在引用古籍时,引用篇目是一种重要的方式。所以说在古籍目录中消失很久的篇目,应该在数字人文时代重新回到目录学的视野中来。
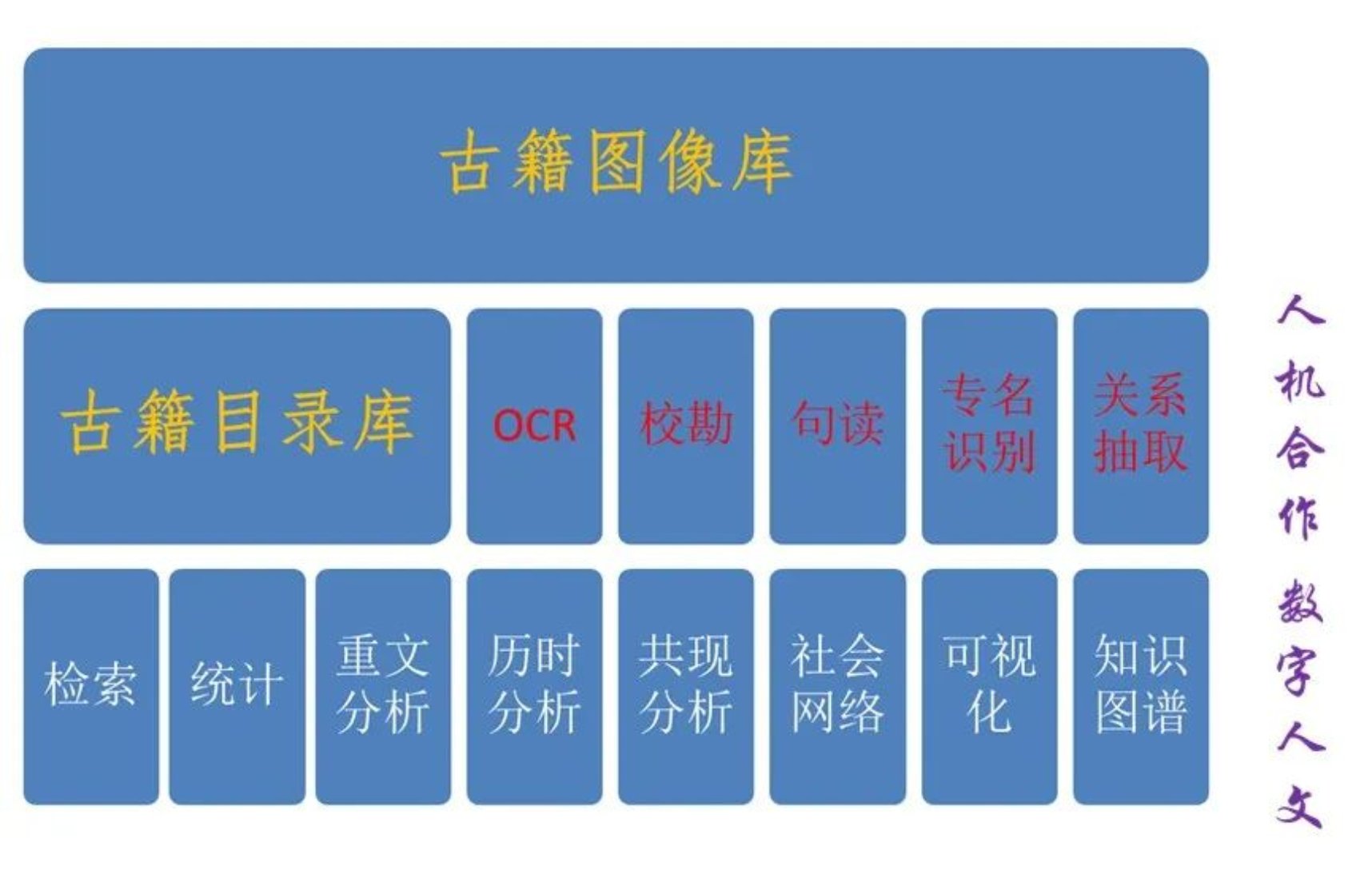
图1 古籍数字化工作示意图
古籍的图像经过OCR文字识别,不同版本的文本可以进行自动校勘,然后可以进行自动句读、专名识别和关系提取等自然语言处理,从而基本上实现半自动化的古籍整理,大大提高古籍整理工作的效率。在此基础上,可以继续做检索、统计、重文分析、历时分析、共现分析、社会网络、可视化、知识图谱等各种分析和研究,达到数字人文的目的。可以说古籍资源库建设是基础,再加上支撑各种分析的古代知识本体库,两者构成古籍数字化研究的基础设施。现在大多数古籍数字化研究都集中在应用层,做底层工作也就是古籍数字化基础设施的太少了,就是因为有这个瓶颈在,所以古籍数字化研究一直处在不愠不火的状态。如果能很好地夯实和共享基础设施,我们必将迎来古籍数字化的发展和繁荣。
人文学者擅长解读经典文本,比如说汉代的经学家秦近君解说《尚书》“粤若稽古”四个字的解说就达三万言,这当然有些夸张,但人文学者的确就是有这个本领。随着时代逐渐靠近现当代,留存下来的史料越来越多,如何处理这么多史料则成为一个不能回避的现实挑战,仅靠学者阅读显然是无法实现的。比如我们要研究近代中国“科学”这个观念的引入和涵义变迁这一观念史的题目,就涉及太多的史料,除了书籍还有杂志、报纸、文件档案,等等。并且“科学”这个概念还有不同的名称,所以我们必须重视和充分利用数字人文的方法。傅斯年在《历史语言研究所之旨趣》中提出我们要“运用新材料,发现新问题,采取新方法。”我们认为数字人文就是这个意义上的新方法。然而应用数字人文方法的关键就是要让研究材料“可计算”,“可计算”是数字人文的核心概念。但是大家往往把“可计算”误解成“可计量”,认为要把材料都转变成数字才能计算。实际上“可计量”只是“可计算”概念中很小一部分内容。除了数字以外,更多计算的对象是各种关系。因此,数字人文的第一步是获取资源,第二步是将其结构化加工,这个结构化实际上还包括字段的标准化和属性的关系化。
我们用北京大学数字人文中心开发的“经籍指掌”来做解释说明,这个项目得到了国家古籍数字化专项的资助。根据《中国古籍总目》的调查结果,现存古籍大概有20万个品种,50万个版本。所以这个系统第一期的数据是在《中国古籍总目》的基础上加上七史艺文志、《四库全书总目》,目的是想覆盖古今所有典籍的品种,所以后续还会补充历代补史志艺文志和各种专科目录的数据。我们已经对亡佚古籍的品种数量做了初步考察,估计大约在15万到20万种之间,也就是说中国历史上存在的古籍大概在35万到40万种之间。我们加工这些书目文本,先通过计算机和算法进行自动记录拆分和字段提取,这样就完成了初步结构化。然后通过人工进行校对、书名和作者(包括作者朝代)规范以及数据补全,最后进行典籍品种认同。经过认同的书目数据,如果规范书名、作者朝代、规范作者名相同,那么两条数据就会被认为是同一种书,这样计算机就能自动进行品种关联和计算。我们目前开发了“检索统计”和“类目演化”两个功能,其中“检索统计”可以满足“查一类之书”和“查一书之著录”的需求。“类目演化”是我们尝试的一种分析功能,通过典籍类目的演化探索古代学术的变迁,实现这种分析的前提是不同目录中的典籍品种完成了认同关联。比如通过系统演示,《新唐书·艺文志》中经部乐类的典籍基本来自前代目录的经部乐类,有个别来自集部总集类,这些书在《宋史·艺文志》保持著录在经部乐类,到了《四库全书总目》,除去亡佚的,一部分进入子部艺术类,一部分进入子部小说家类。点击进去,可以看到具体是哪些书,从而实现了典籍类目演化的可视化分析。对于“查一书之著录”的需求,历代目录资源很多还没完成数字化,是今后目录数据库建设的重要瓶颈。而从典籍品种扩展到典籍版本,很多基础的工作还不够完善,因为版本认同在古籍普查工作中就没有完全解决,此外针对历史上已经亡佚的版本,也还有更多工作要做。总之,目前古籍目录数据库的建设已经取得一定的规模和成绩,但依然任重道远。
〔注:本文发表于《数字人文》2023年第3期“系列笔谈之七:古籍目录数据库建设”,引用请以该刊为准。〕
|

.jpg)








