|
引言
识典古籍是古籍数字化三十年以来,中国大陆目前面向大众开放的最大规模的古典文献阅读与整理平台,由北京大学数字人文研究中心与抖音集团联合打造。
识典古籍阅读平台涵盖了儒释道三家基本核心典籍,预计到2024年底,将实现《四部丛刊》、《四库全书》、《大藏经》、《道藏》等约7000种文献的全部上传和公开访问。平台与海内外古籍收藏机构广泛合作,持续不断增加上架古籍。
识典古籍整理平台是目前唯一能够对古籍进行全流程智能化处理的开放平台,该平台利用AI技术完成古籍整理的每个步骤,极大减轻了人工的工作量。
识典古籍不仅可以帮助学者对古典文献进行整理、检索、学术研究,还依托今日头条、识典百科、抖音等媒体,在数字环境下推广中国传统文化。
一、古籍阅读平台
(一)书籍查询
当我们需要查找古籍时,可以按照书库的目录进行浏览,根据经、史、子、集、佛教部、道教部不同分类,找到所需的古籍。
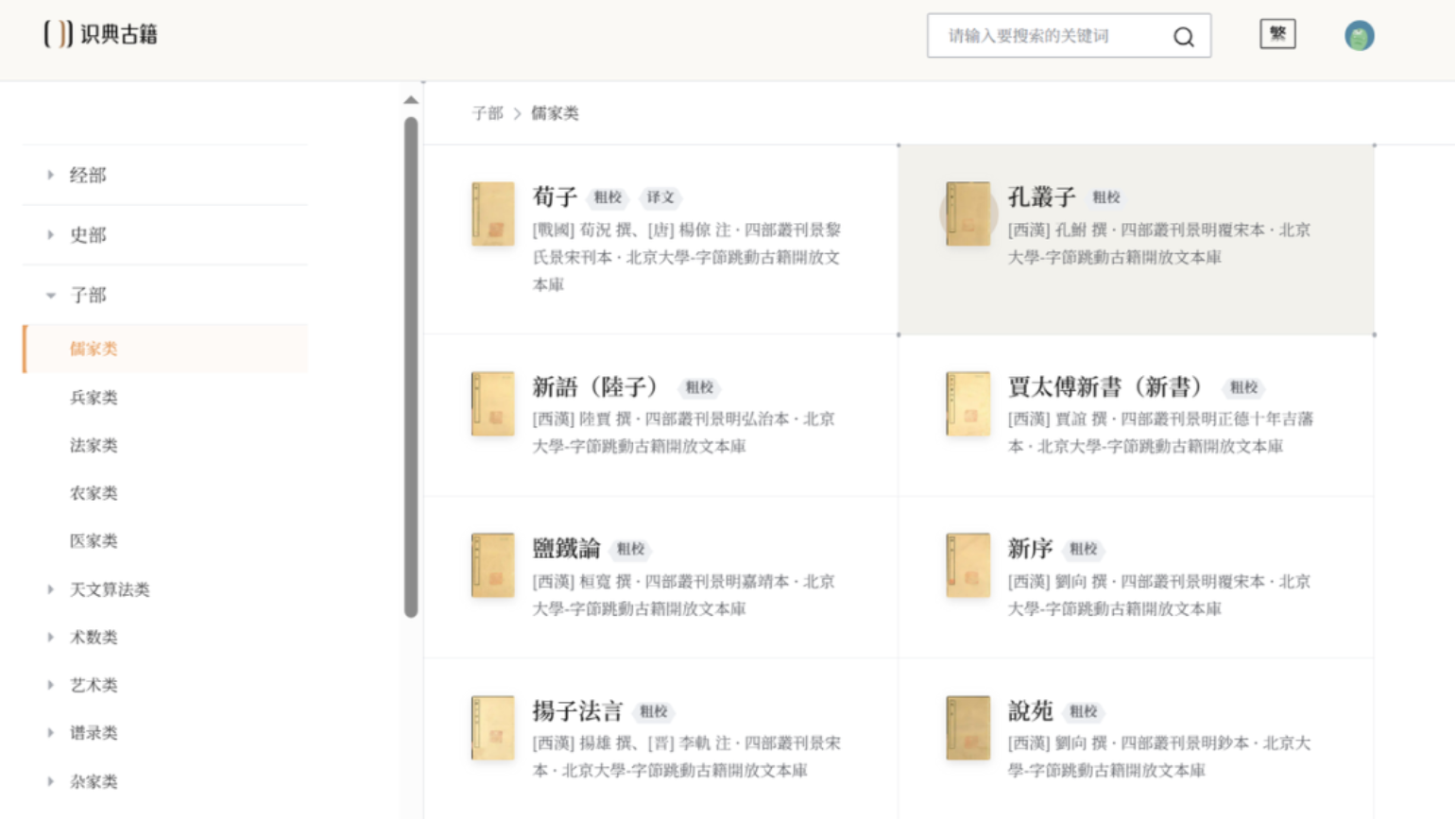
还可以通过搜索找到相关的书籍,如我们要阅读“孟子”这本古籍。搜索栏搜索,就可以看到《孟子》。识典古籍具有阅读记忆功能,点进去就可以直接跳转到我上次阅读的位置。
阅读界面含有标题、分段等基本的书籍结构、并标有现代标点。
(二)图文对照
阅读平台提供了图文对照的功能,文字内容和古籍原文图片可以相互对照。在滑动页面时,文字对应的图片也会相应变化。
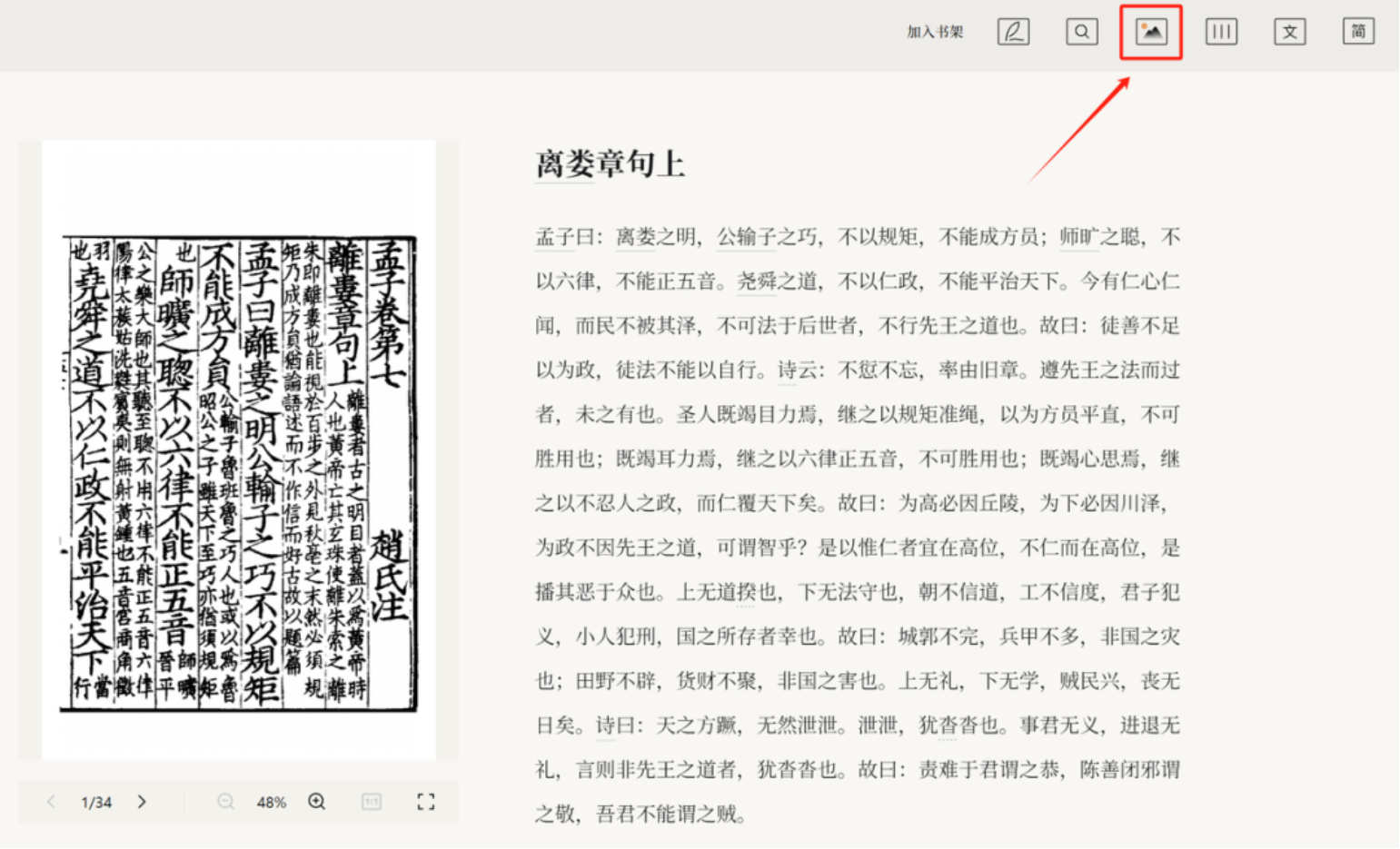
值得一提的是,以往查看古籍图像时需要费眼力去找寻对应的文字,现在可以利用定位原图的功能直接将文字定位在图像中并高亮显示,从而方便阅读。


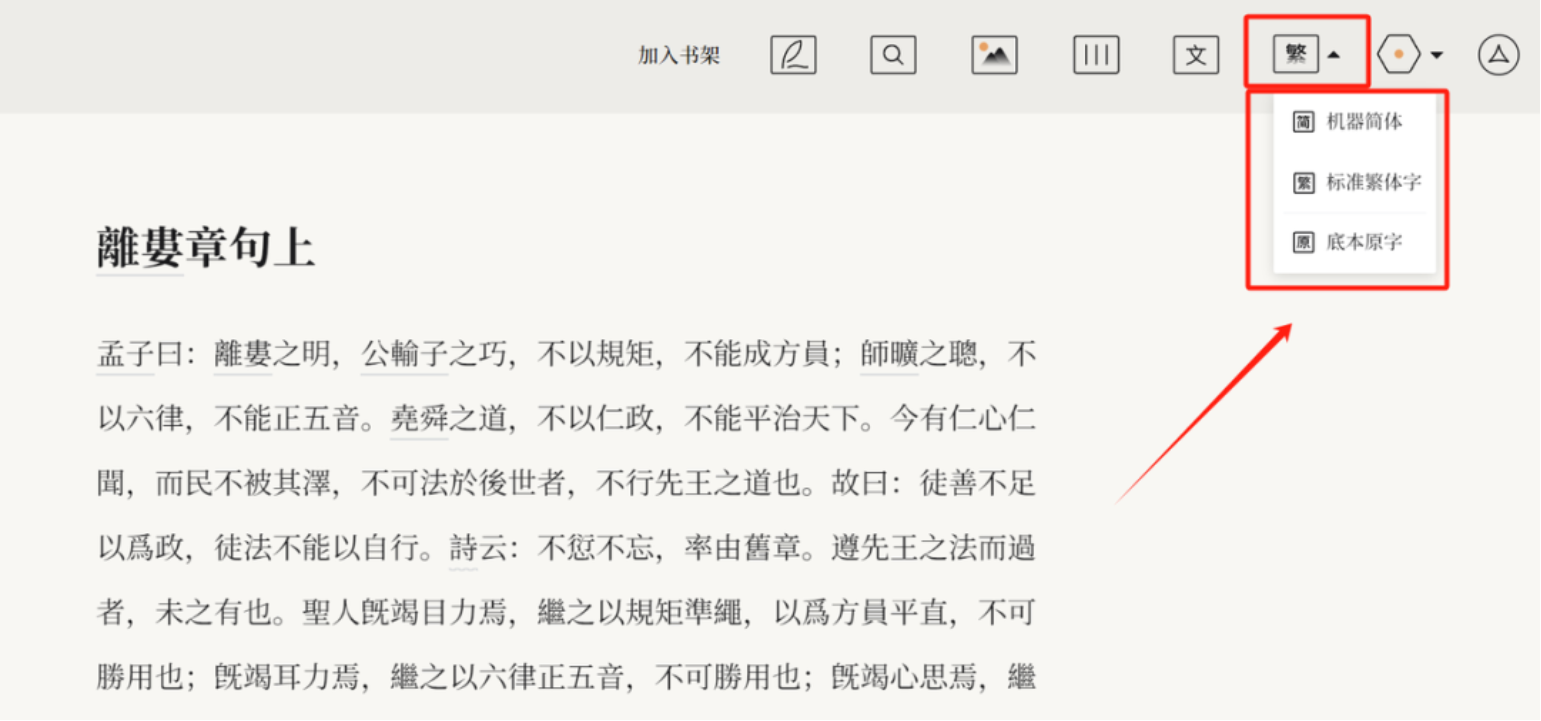
(三)繁简转换
文字显示提供了三种模式选择:一种是简体字模式,一种是标准的繁体字模式,还有一种是保留俗体字、异体字原貌的底本原字模式。用户可以根据需要选择不同的模式。
(四)隐藏注疏
阅读平台具有隐藏/显示注疏的功能。
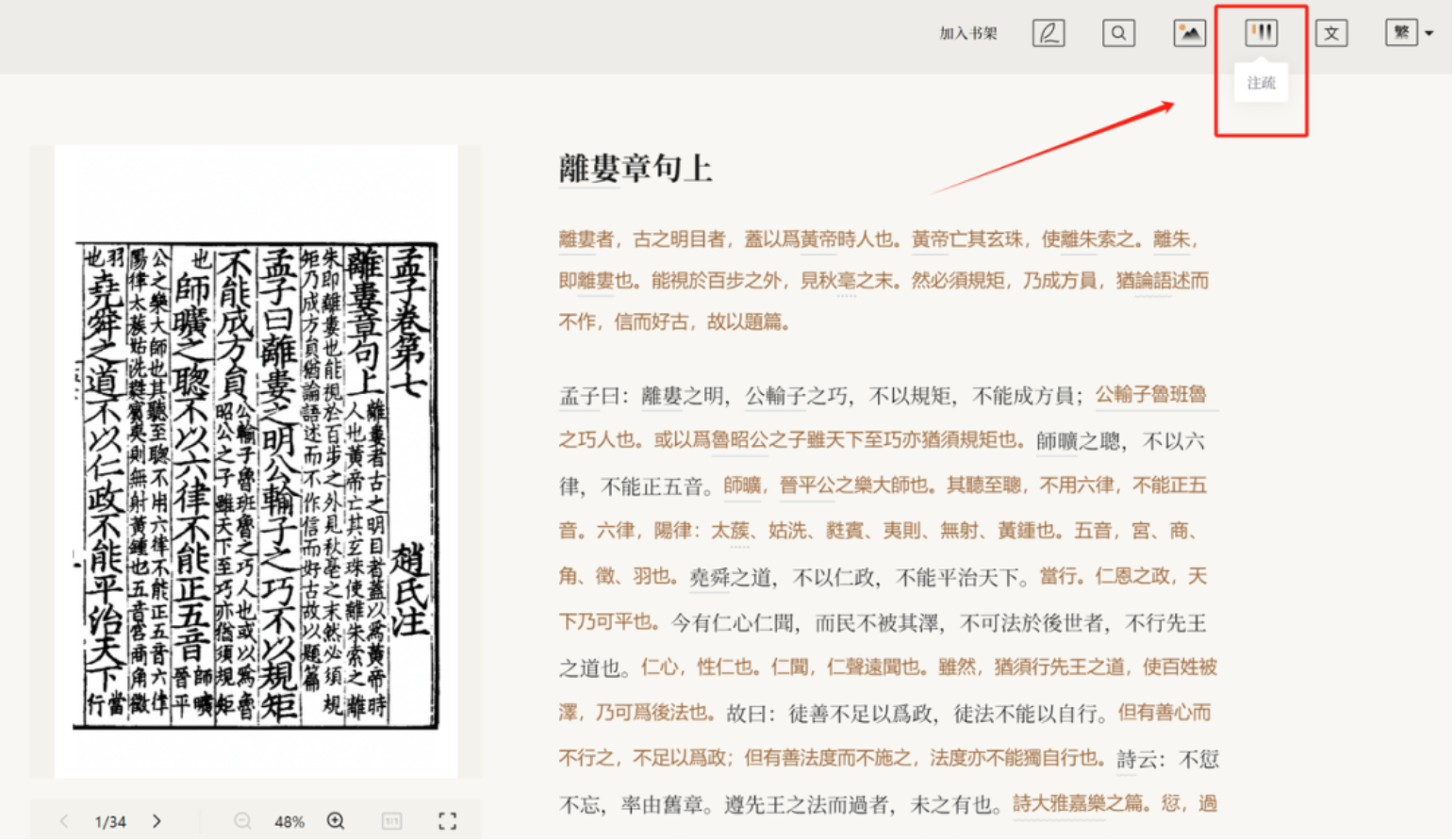
除此之外,识典古籍平台还拥有许多阅读辅助工具。
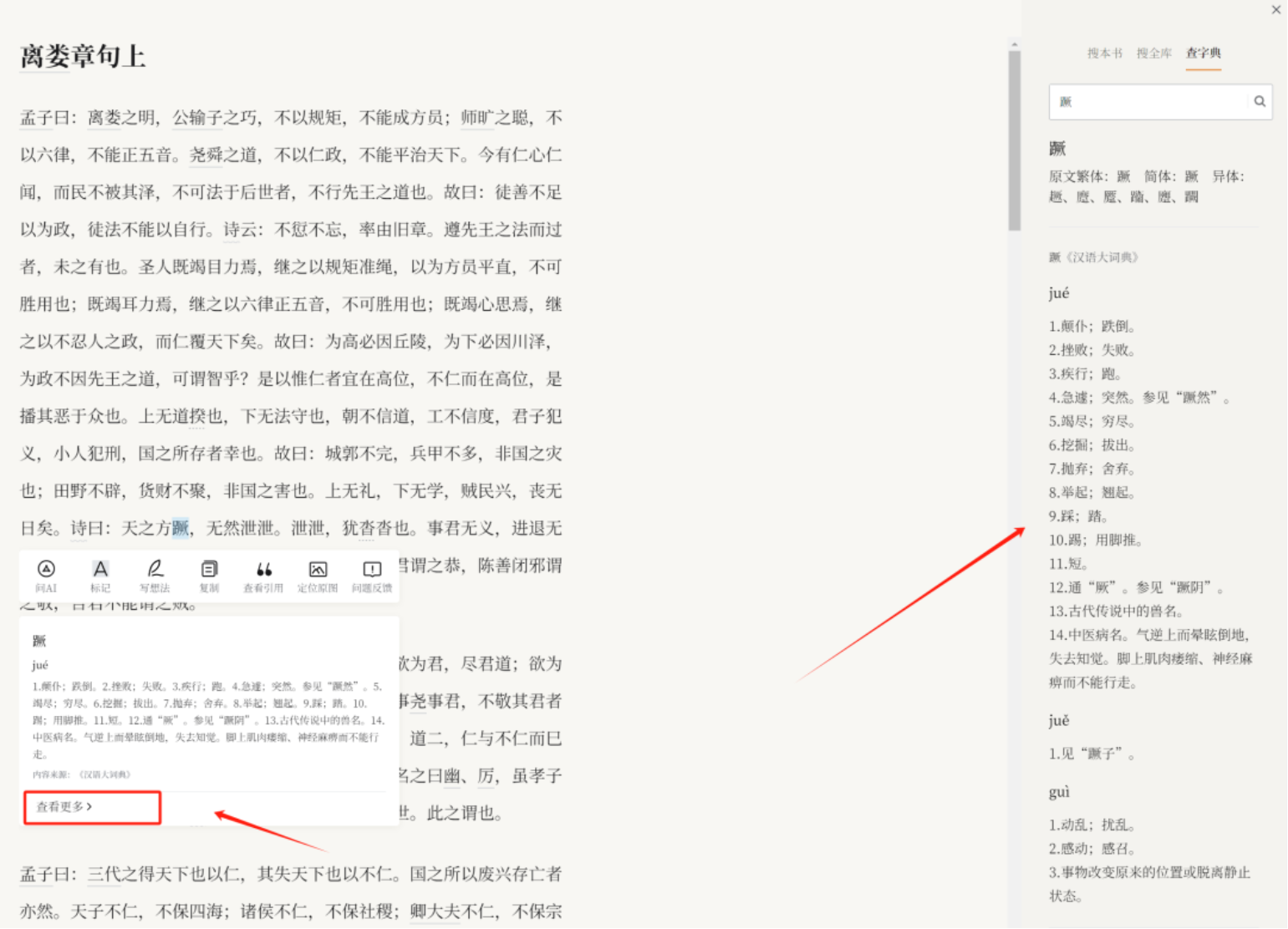
(五)字典注释
阅读中遇到疑难字词,点击该字词就会弹出《汉语大词典》《康熙字典》和《说文解字注》的相关词典数据,帮助人们理解词义。
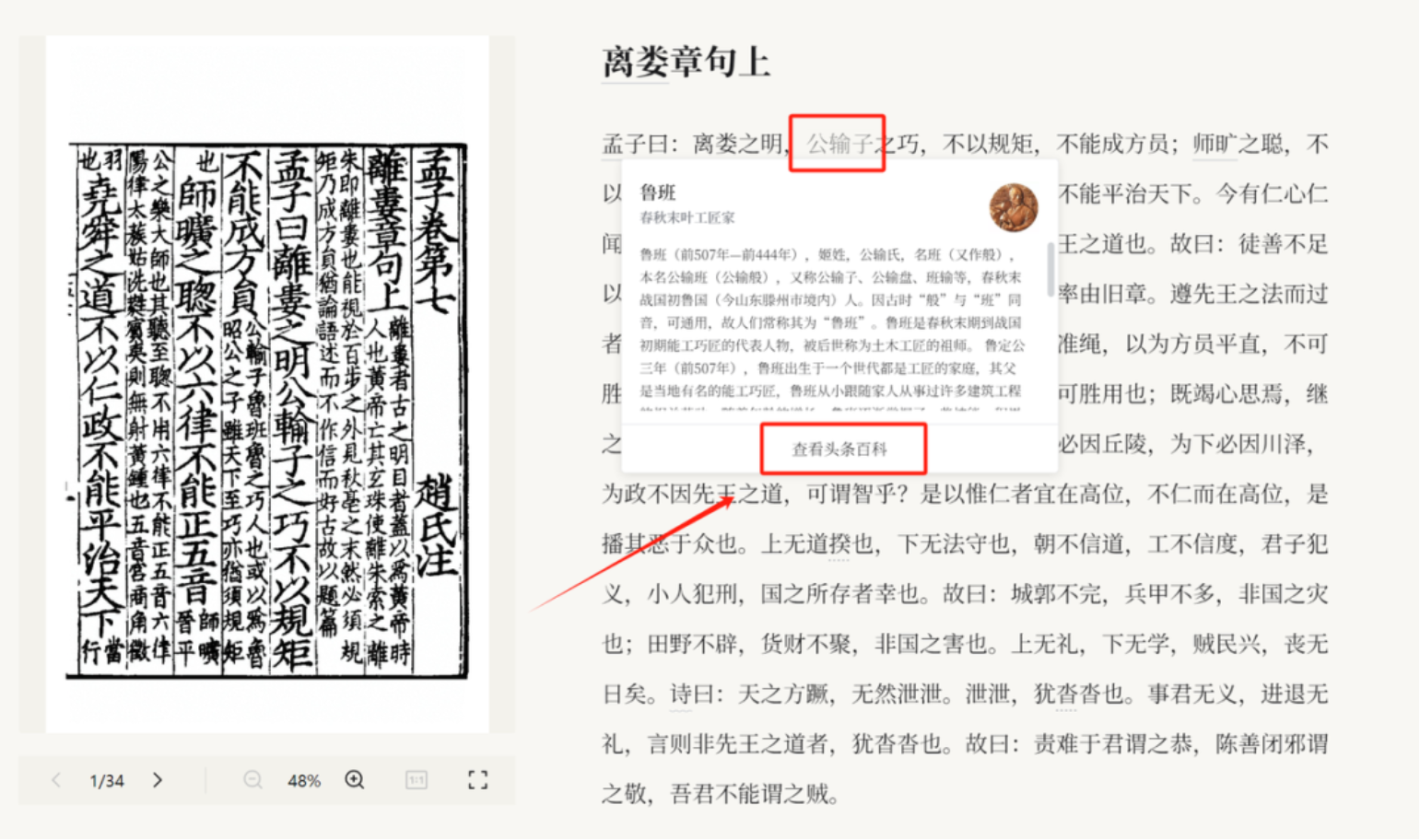
(六)实体百科
平台针对重点的古籍做了命名实体识别,古籍中的人名、地名、时间、职官、书名都以下划线的方式标记出来。点击实体,便会对应到识典百科中,能够让人们进一步了解这些不熟悉的专名,达到增强阅读的效果。
同时,也可以选择隐藏实体标记。
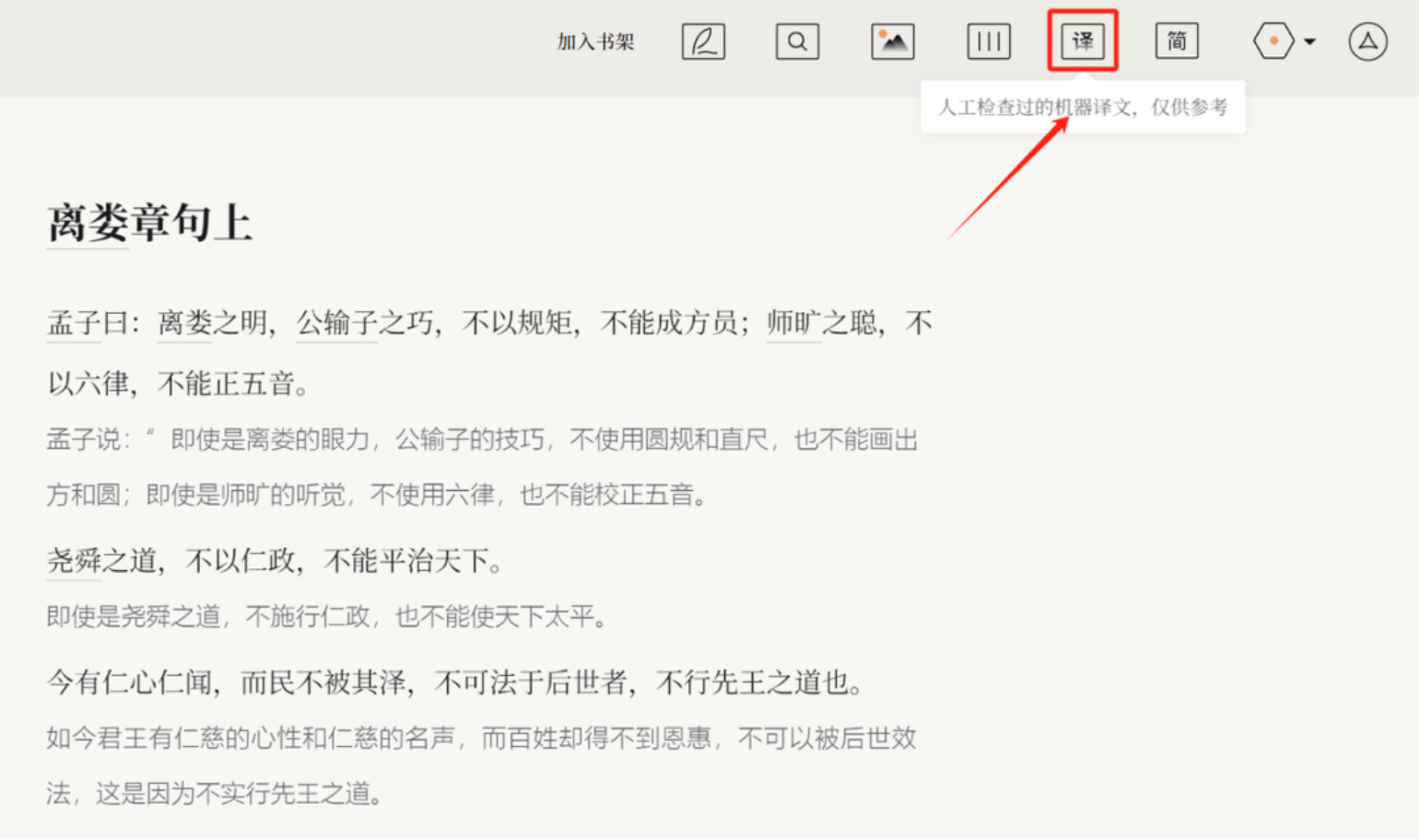
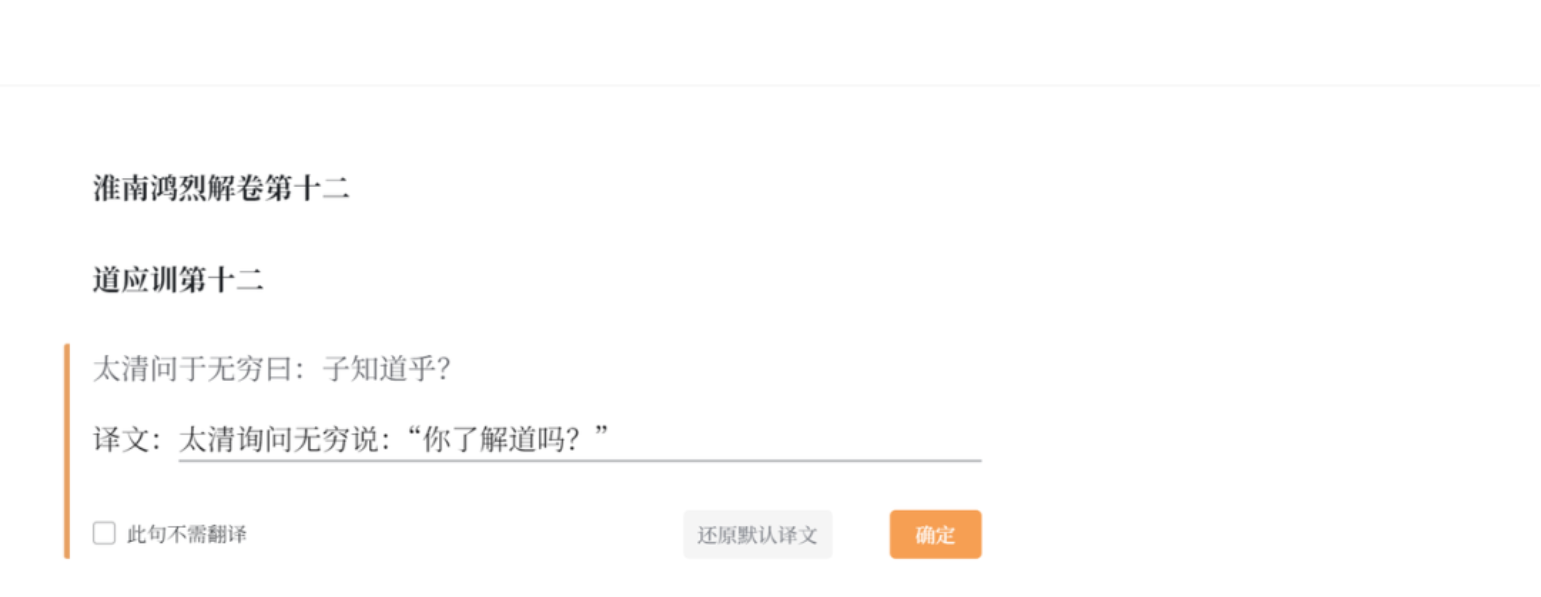
(七)文白翻译
针对一些经典古籍,平台有文白翻译功能。点击这里,可以选择隐藏或显示译文。这些翻译是自动翻译后并经过人工修改的,可以帮助人们更好的理解古籍原文的含义。未来平台还考虑引入英语、韩文等外文翻译。
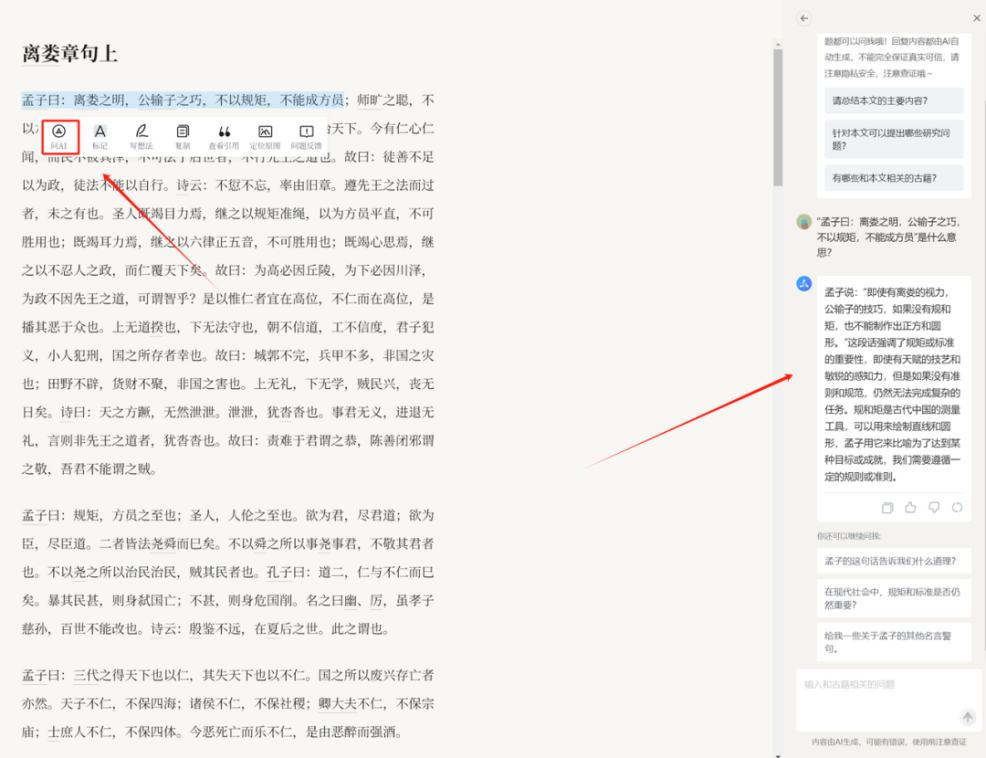
(八)AI问答
平台还引入了大型模型的AI问答功能。例如,当遇到一些不太理解的语句子,可以唤起AI问答助手进行解答。对于整篇古籍原文做总结,或者对任何与古籍相关的内容进行提问,都可以在此进行智能问答。另外,还可以向AI助手询问与该篇古籍相关的其他文本。AI助手会生成相关内容,点击生成的链接,将直接跳转到识典古籍平台的对应古籍页面。
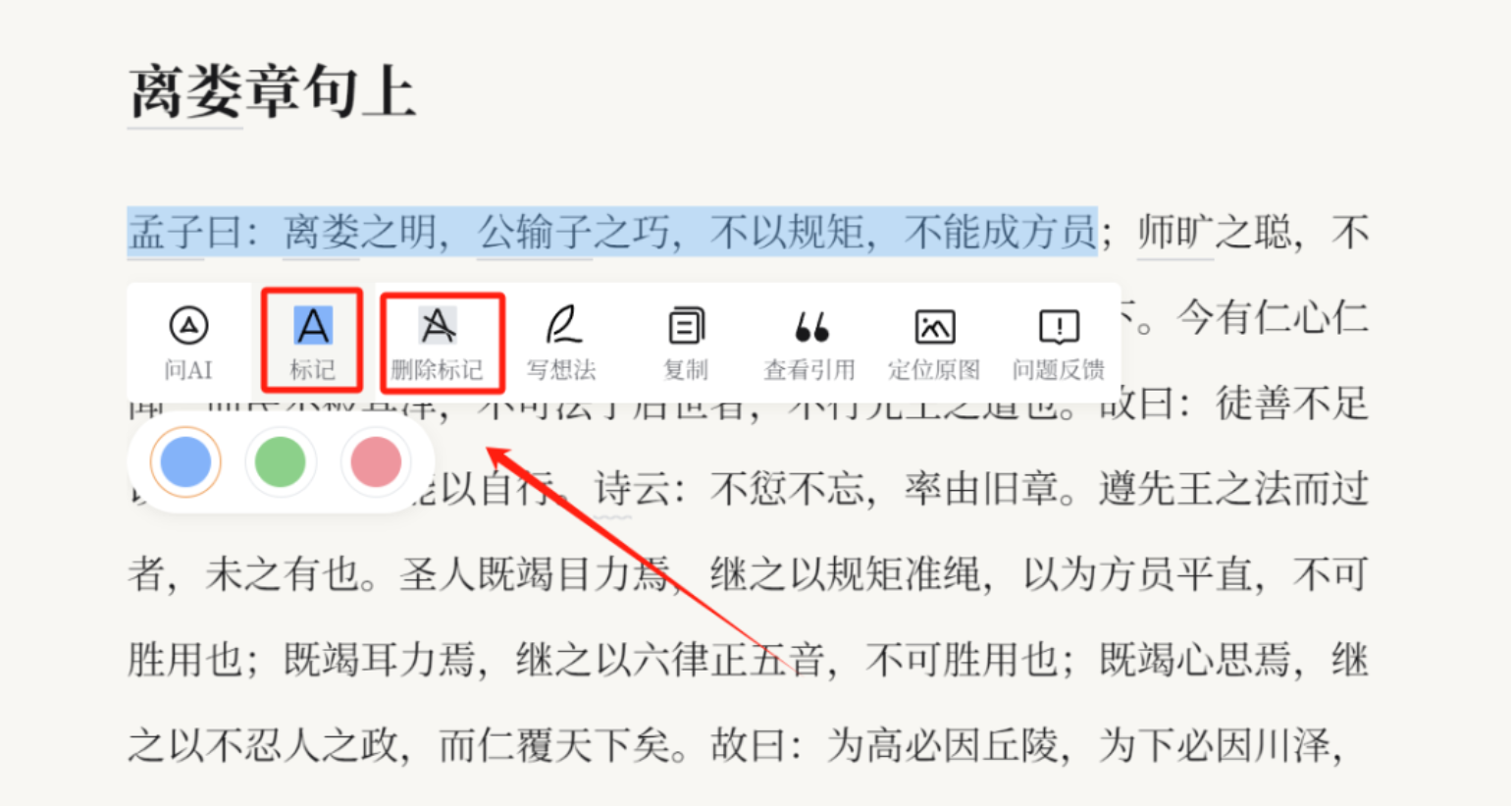
(九) 笔记阅读
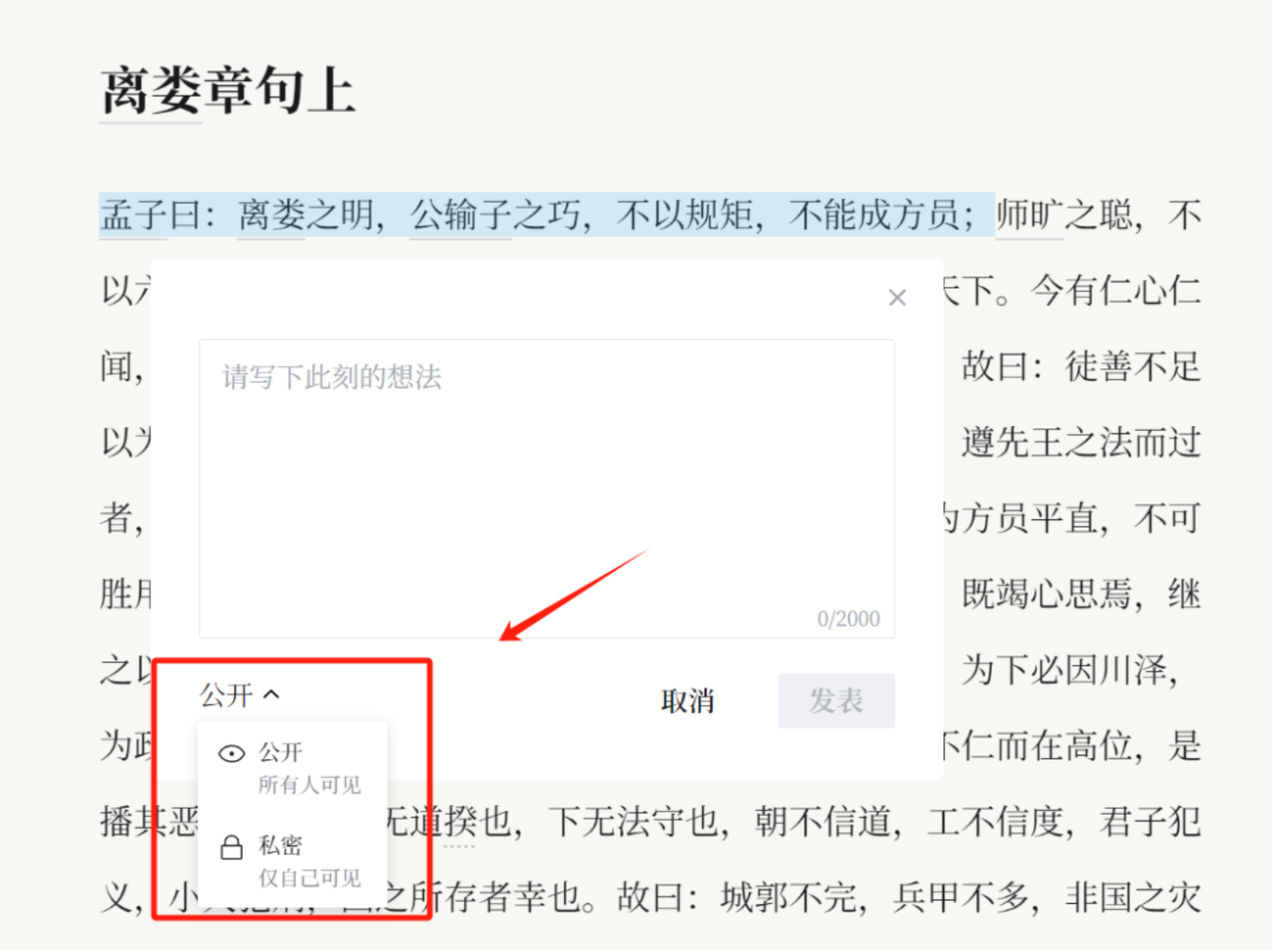
阅读时,如果您发现重点的语句,可以标记划线。
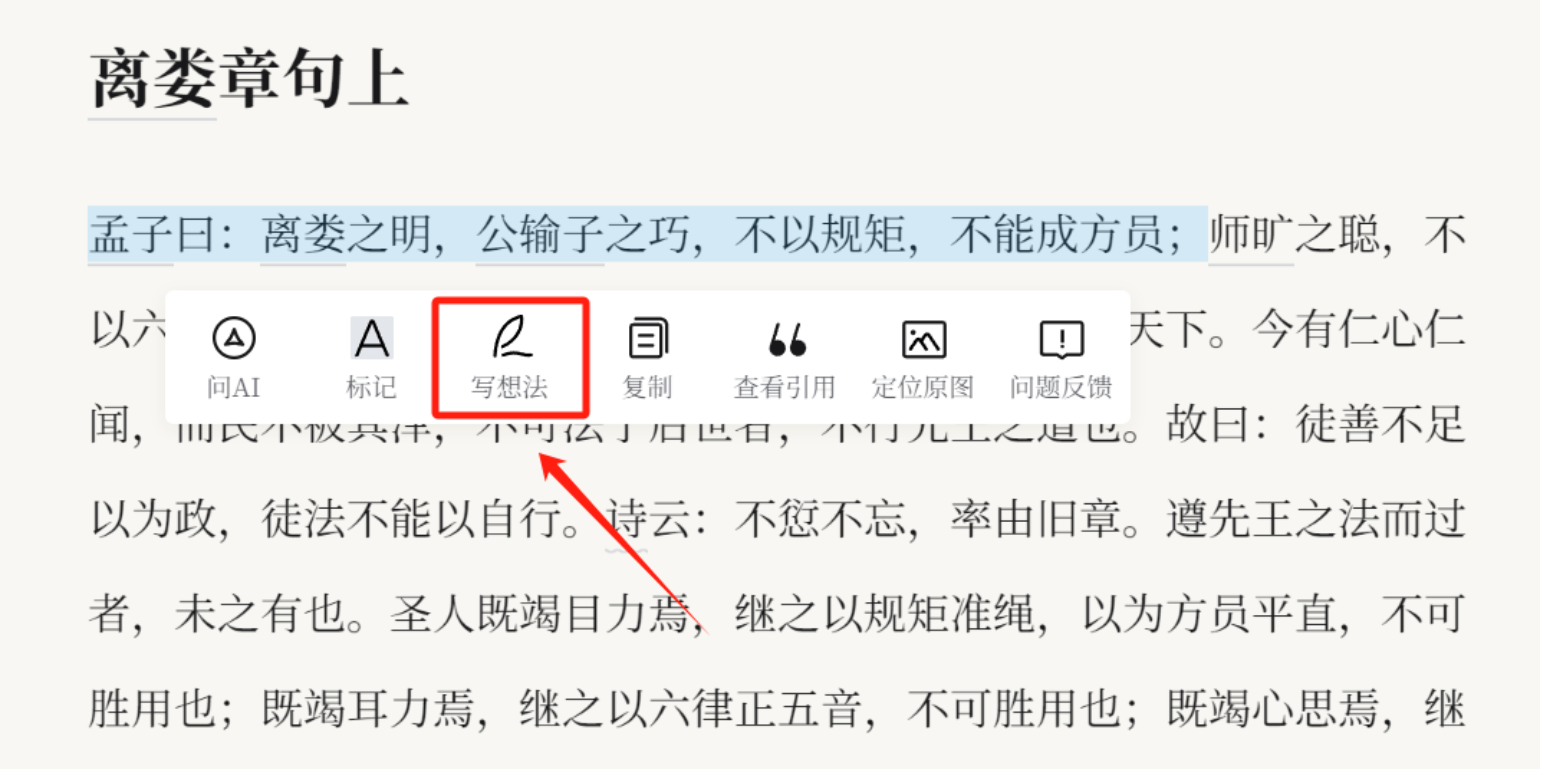
用户还可以记录自己的想法,笔记可以选择公开或者保持私密。
在平台上,用户也可以选择查看其他人的笔记。通过这些笔记,平台构建了一个互动阅读的社群。

(十) 分词检索
识典古籍的检索功能不仅可以进行精准匹配,还可以进行分词检索。
以《淮南子》中的一句话为例,如果选择精准匹配,将直接定位到《淮南子》原文。
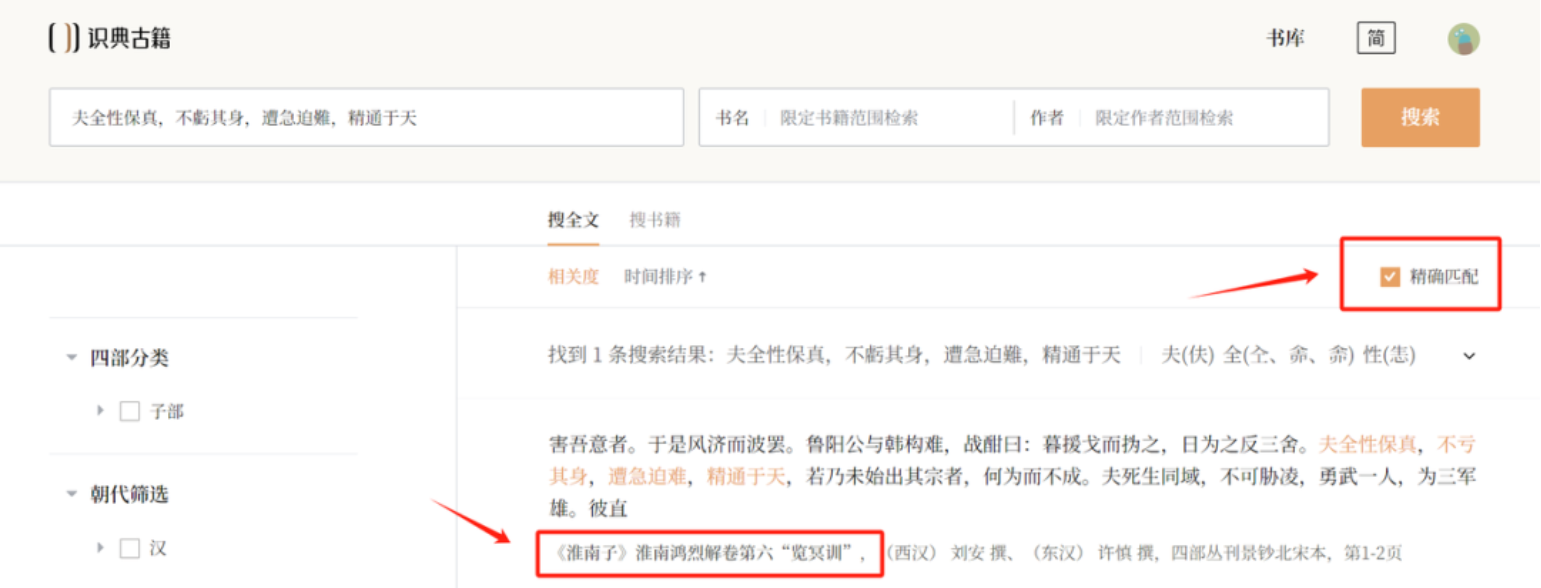
如果选择分词检索模糊匹配,系统会通过分词的方式展示与这句话意思相近但词汇不完全相同的语句。
例如我们会发现《论衡》和《吕氏春秋》种的相似语句。该功能将极大地方便古典文献学者进行互见文献研究,并可以更多的挖掘搜集相关古籍文本。

二、古籍整理平台
传统的古籍整理流程包括以下步骤:搜集版本、确定底本和校本、在底本或工作本上进行标点和校勘工作。完成这些步骤后,交付排版公司进行文字录入,最后再交付出版社进行三审三校的出版工作。
毫无疑问,这个流程需要大量的人力投入。然而,智能技术的发展使得许多机械重复的工作可以通过人工智能来解决。为了解决传统古籍整理过程中的一些痛点,识典古籍整理平台应运而生。
整理平台包括文字识别、文字精校、文字校勘等文字录入检校环节,主要运用OCR技术、文字匹配技术等。自动环节运用与人工智能相关的自动标点、自动分段、自动校勘、命名实体识别、自动翻译等功能。在人机协作环节,有结构整理、标点校对、实体校对、译文改写等,通过人机协作对计算机结果进行进一步修改。最终生成一个可开放共享的古籍文本,并发布在阅读平台中。
(一)发布任务
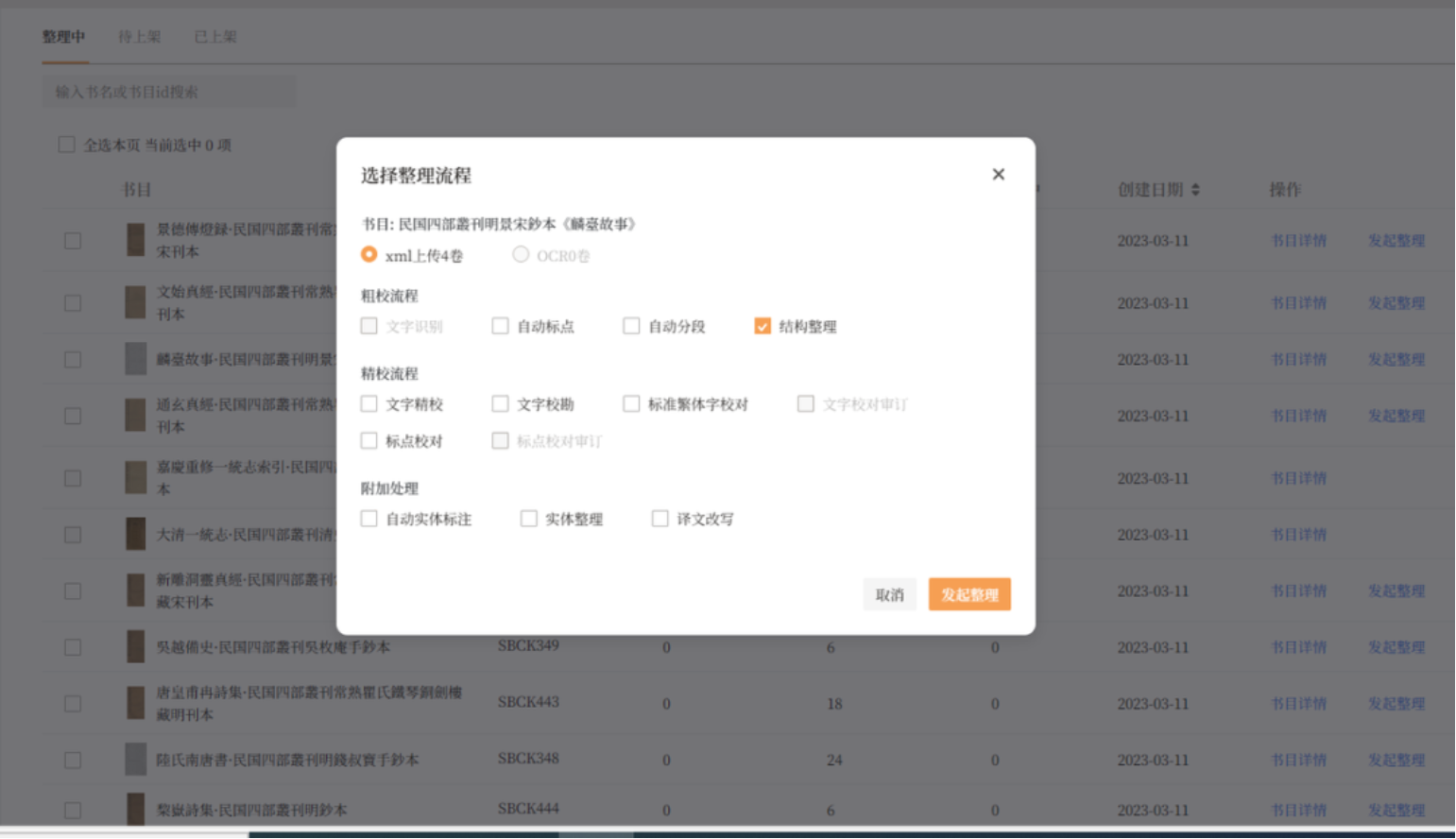
新建古籍条目后,整理平台可以通过xml、图片两种方式上传古籍数据。上传数据成功后,可以根据实际工作需要选择不同的整理流程。
(二)书元信息
针对创建的古籍,可以对书籍的基本信息,如四部分类、成书年代、书籍简介、作者、版本等进行著录。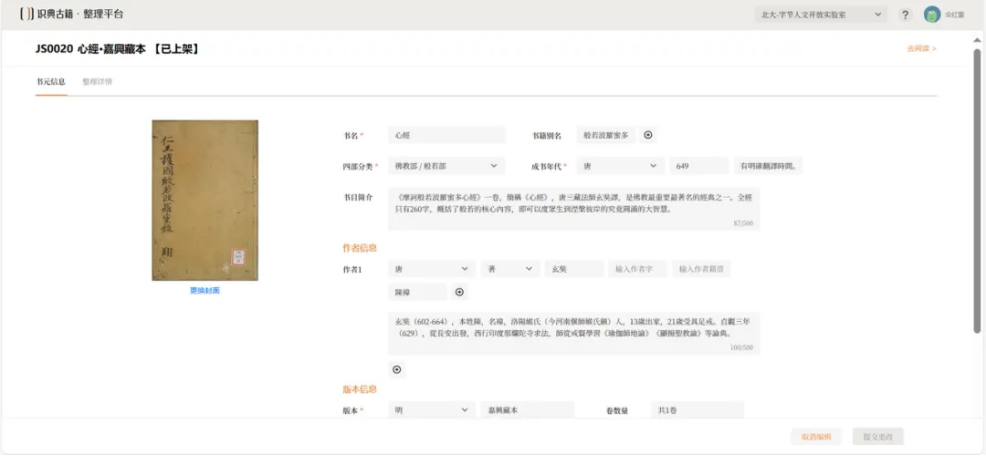
(三)文字识别
在整理平台上,按书籍、卷,上传图片后。OCR技术可以将古籍图像的文本进行识别,这是OCR识别出来的文字结果,对于OCR不确定的字,会有颜色标记。以行对齐的方式,进行按行匹配。这样会方便地、便捷地定位这些有问题的文字,并同底本进行修改。
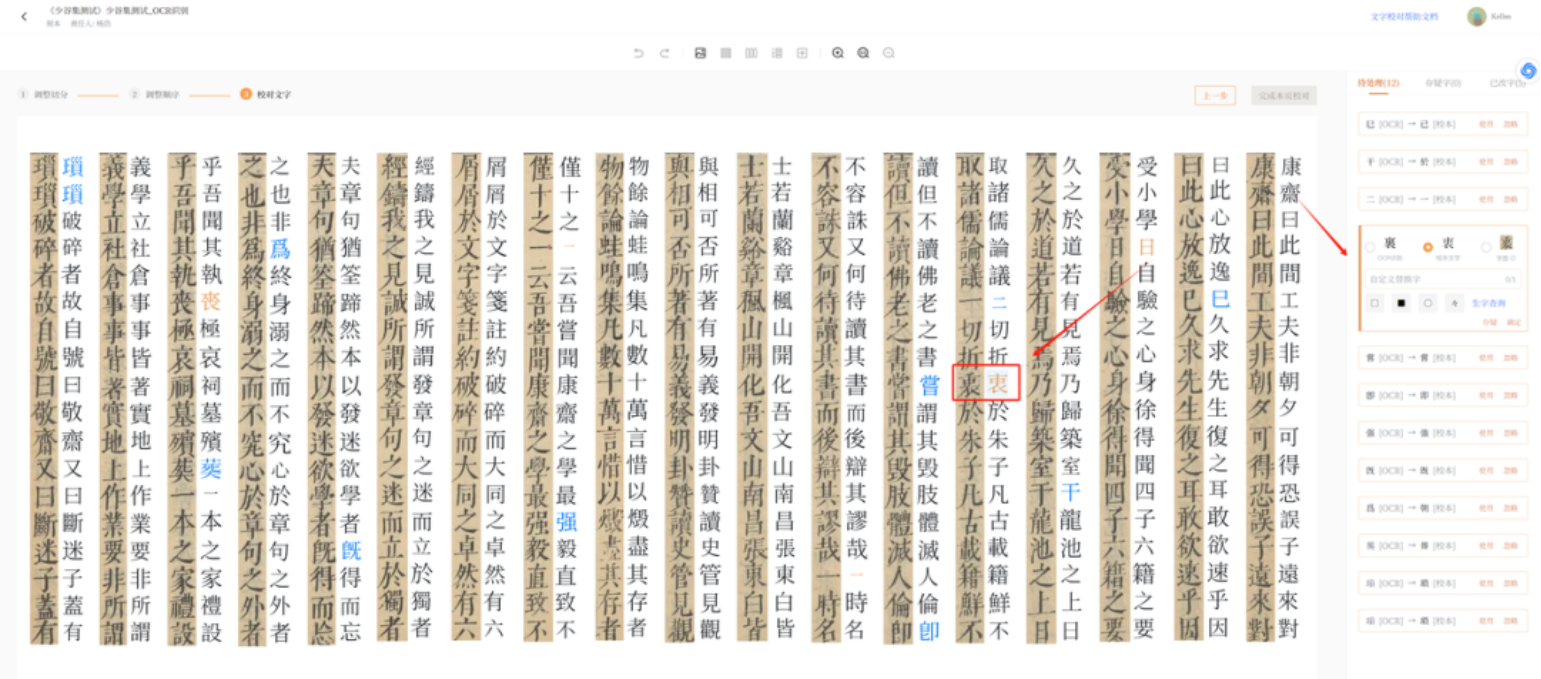
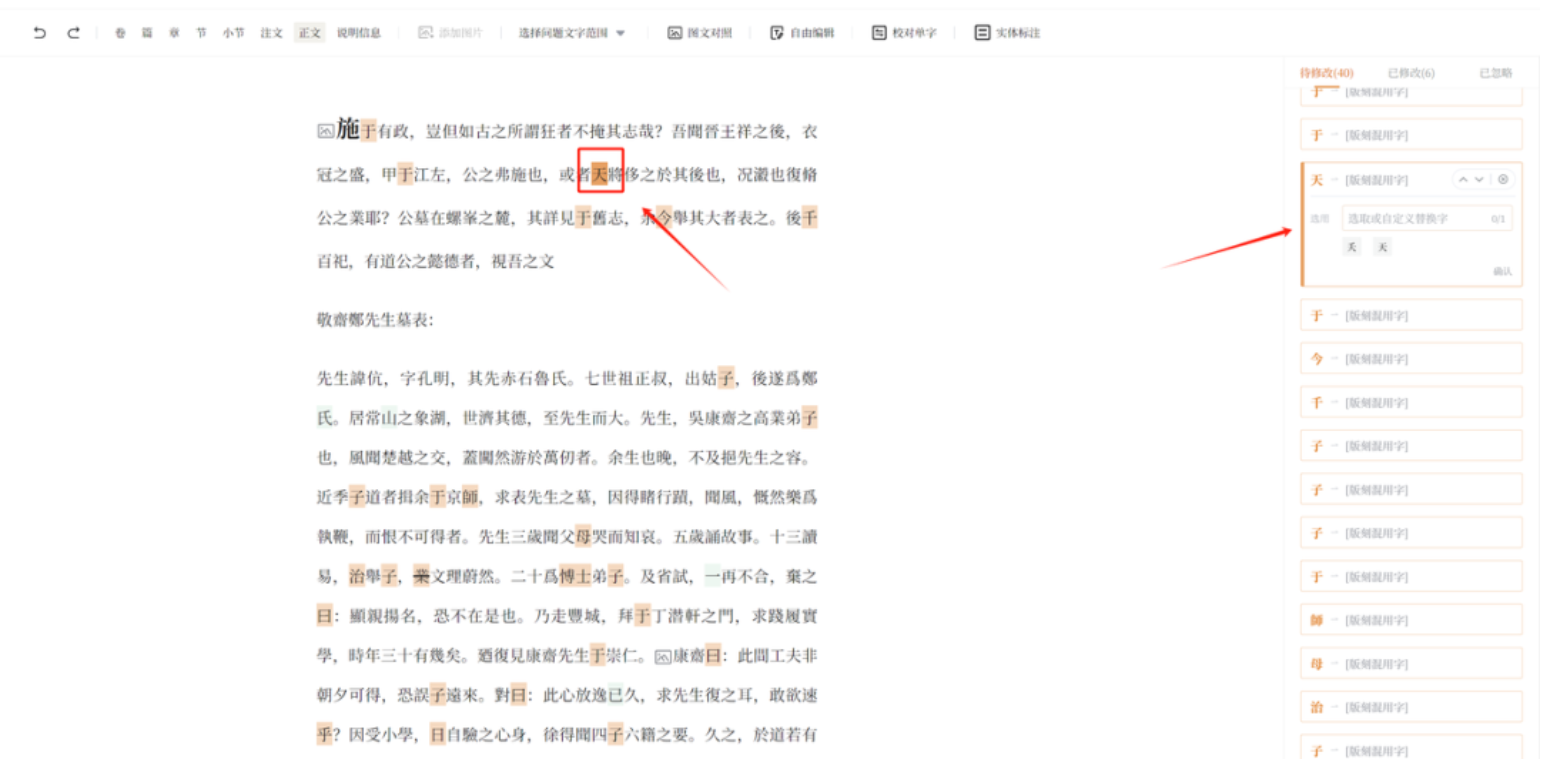
(四)文字精校
在文字精校环节,将两套不同的文本进行匹配,快速定位可能存在问题的文字。当点击问题文字时,图片也会显示文字位置。确定文字是正确的还是错误的,并进行修改。
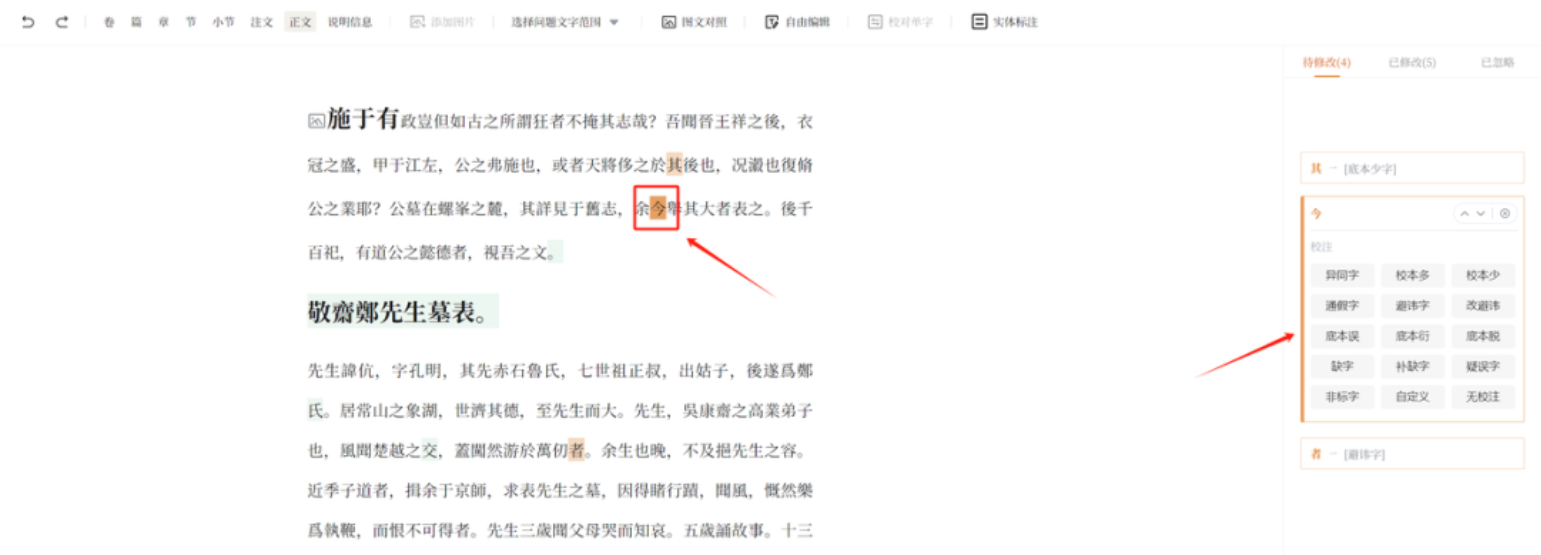
(五)文字校勘
文字校勘环节可以对底本文字的错误做修改,并且把差异写成校勘记。
(六)结构整理
结构整理是指对古籍的标题、分段、正文、注释等进行标引。其工作主要是对经过自动标点、自动分段的古籍文本进行修改。在这个环节,我们可以选择卷、篇、章、节等标题进行标引。也可以根据原书图像或语义对古籍进行分段。如果正文、注文OCR识别有错误,也需修改。
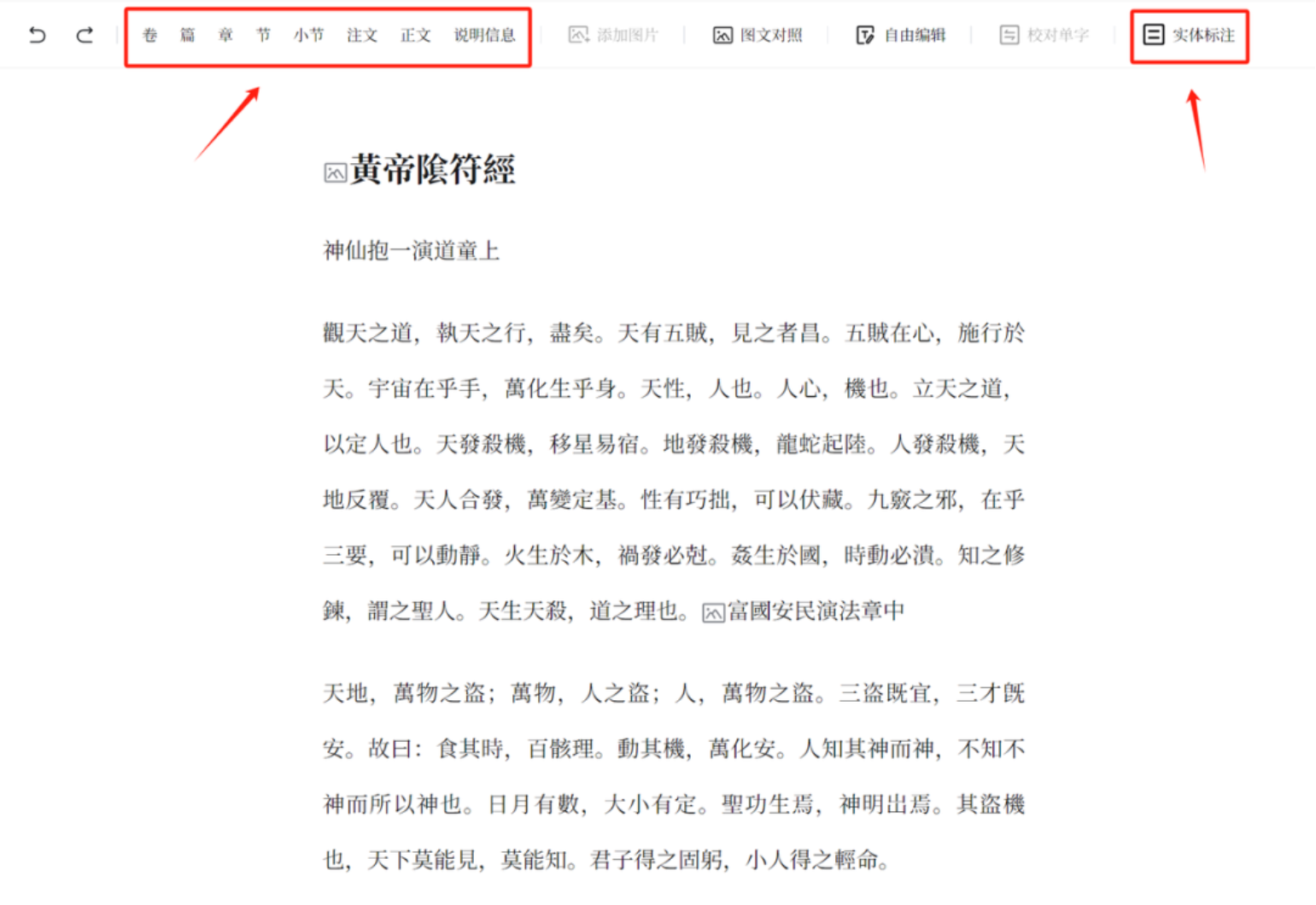
页面内可显示对应的图像。
(七)校点校对
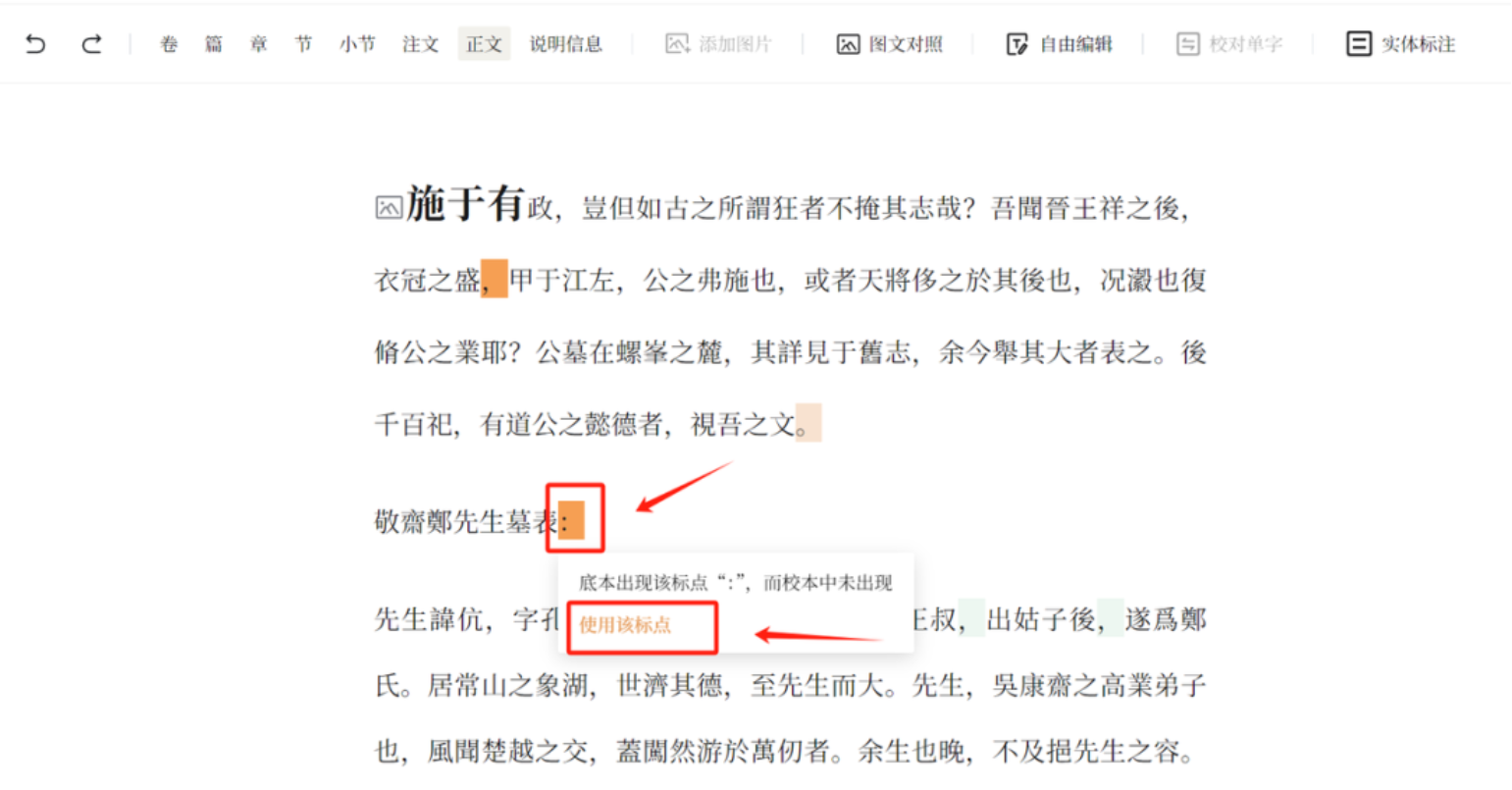
标点校对环节可以通过两套自动标点对结果进行匹配校对,并把差异标点用颜色显现。两套标点结果相同的地方,不进行颜色标记;不同的地方则用不同颜色标记,这样就可以快速找到标点容易出现问题的地方。
(八)实体校对
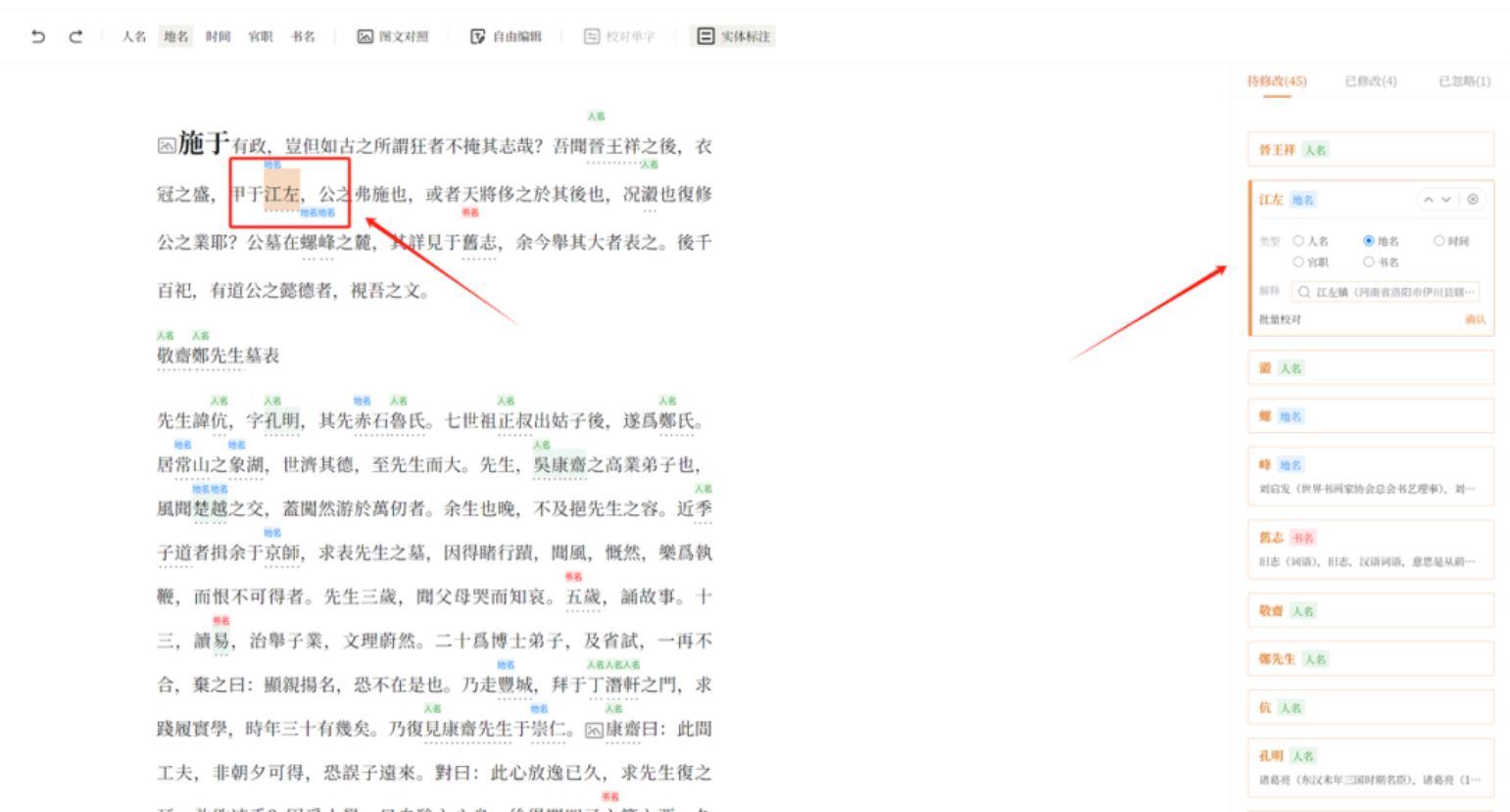
自动实体识别可以对人名、地名、书名、时间和职官进行标记。这些实体需要人工再进行修改,找出其中的错误或缺漏。
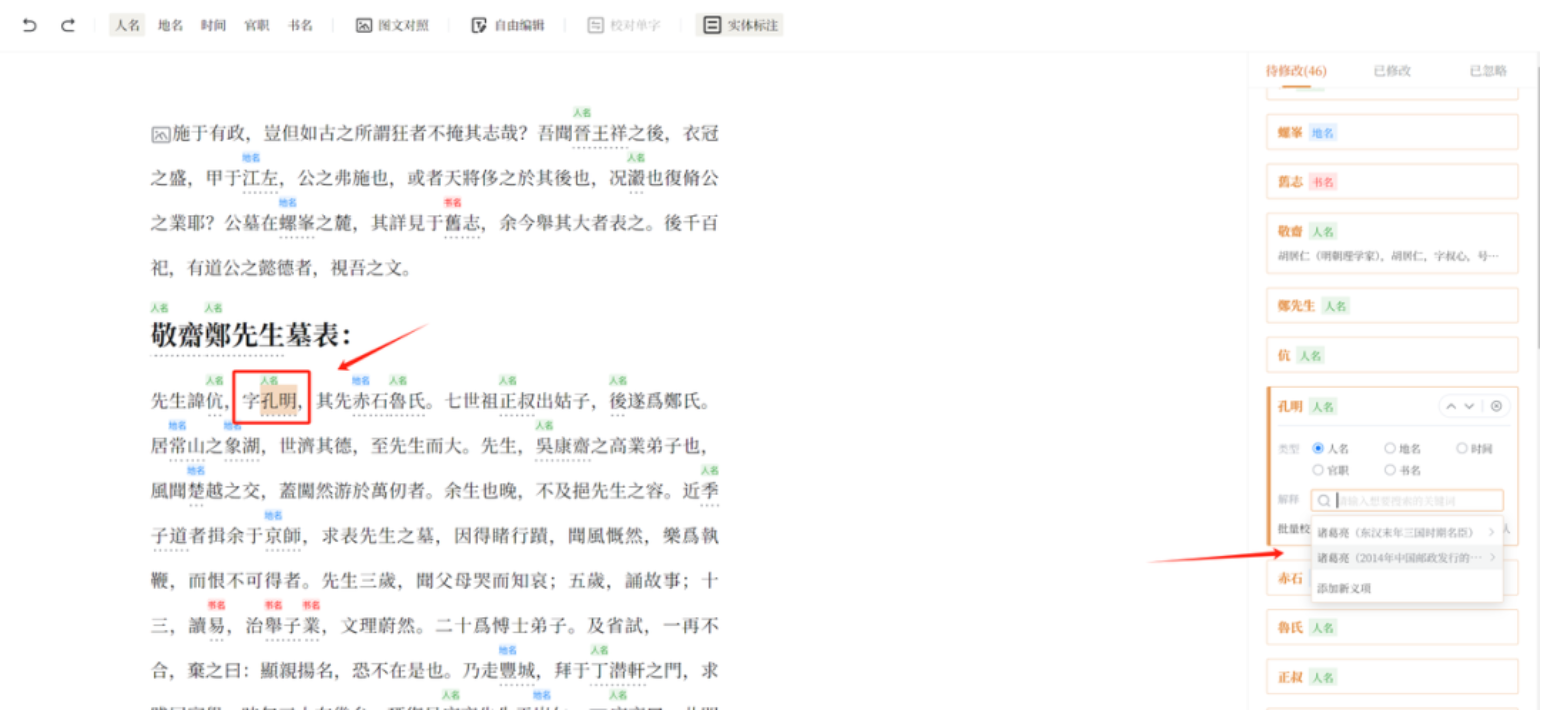
此外,识别到的实体信息需要整理者与百科相对应。例如,识别到的“孔明”可以选择链接到相关百科页面上。
(九)译文改写
在机器翻译完成后,可以对这些自动翻译的语句进行人工校对和修改,从而保证译文的准确性。
结语
识典古籍是一个开放共享的古籍智能平台,集古籍阅读、古籍整理、古籍研究于一体,共建了一个面向大众的古籍社群。阅读平台提供了优质的阅读体验与一系列辅助阅读的工具,改变了古典文献的传播方式。整理平台利用人工智能技术,在影印、校勘、标点、注释、翻译、索引等方面,大幅减少了人工工作量,为古籍整理工作的进步和智能文献学的发展做出了重要贡献。
|

.jpg)








